"Com' follow me now!"
Thinking hard about tags - the new black as Ado says - and various conversations I've had recently, mostly with Karl, about ontologies, explicit relationships (hah!), etc.
Say I have a bunch of files that I have, one way or another, already tagged with pertinent, non-private, information.
Say I share that information and/or file with a community style site.
For many of my files - most in fact -, there already are ontologies, as I've mentioned before. On the FileSystem/OS level, such things as Date Created, Date Modified, File Type - could be useful; on the Applications level, well, for instance iTunes (or any MP3 player for that matter) has a very clearly defined ontology: it's called ID3... ID3 TAGS, people!
Let's stick with the MP3 example for now. I'll do pictures after.
Most of my music has pretty clean ID3 tags: artist name, track name, album name, star rating, genre... Ah genre. Tricky thing trying to categorize music. Wouldn't want to be responsible for what happened to Curt Cobain, you know... "Don't pigeonhole my music man!" Anyways. So, iScrobbler watches iTunes and tells AudioScrobbler/last.fm what I am listening to.
I am too tired to do a TCP dump so I don't know what iScrobbler is telling the mothership exactly but I would like to think it's sending MORE than just artist and track name. The ID3 spec makes room for lots of information, but let's stick with the aforementioned four, since things like "Track number", "Track length" and their ilk are too contextual (which album it's off of, how the track was encoded) to be really useful in a "sharing environment". So, I assume Scrobbler is only relaying track and artist names. This is already problematic due to typos, misspellings, differing entry methods - "Cat Stevens", "Stevens, Cat", "Caht Stebenz" - but can be moderated...
Similarly, if Scrobbler relayed the genres and ratings *I*, and everyone else, set for tracks, not only would they have a potential headache on their hands, but more importantly, they would have some VERY valuable information. Cynics in the room are already screaming "yeah, valuable to music companies!", but I rather think "yeah, valuable to music lovers!".
So here's what they do. First, capture and relationally store all ratings.
"1,275 out of 134,548 listeners of 'Wild World' give it 4 stars."
"264 out of 45,843 listeners of 'Cat Stevens' give him 2 stars."
For record companies, clear metrics - for music lovers, clear indicators of quality...
Then, genres. This is where it gets interesting. Store ALL incoming genres associated to tracks, but only actually 'ascribe' the, say, 5 or 10 most frequently attributed.
Next, open it up for community editing, Wikipedia style. Wikipedia proves that if you provide the community with a valuable resource of authoritative enough information, the community will roll up its sleeves and tend the garden.
But it's not valuable enough, not authoritative enough... until you open it up even more...
Ontological APIs. KABLOOIE.
"According to [ your friends | your 'musical neighborhood' | Scrobbler ], this track has been tagged to be of the following possible genres..." If you find one you agree with (betcha ya will!) you pick it, if not, you enter your own, which gets sent along back to the Ontology server... Feedback loop.
[Hrm... Imagine CDDB was open like that... holy cow.]
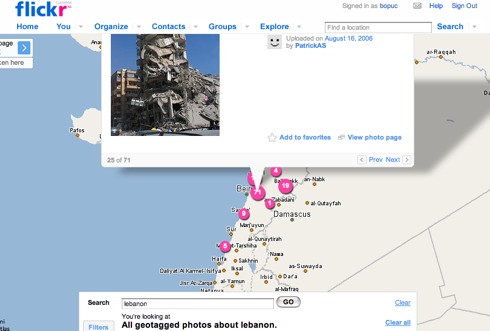
Ok, pictures now. You KNOW I'm gonna say Flickr. I'm also gonna say EXIF and Fotonotes. And tags tags tags tags...
There's alot of talk about the shift from top-down enforced hierarchies to the bottoms-up (hihi!) "folksonomies" and I'm thinking "How nice! We've gone from fascism to marxism! And it took all of... 3 months!"
Democracy, people. Create loose, general ontologies, and let community leaders manage them... In Flickr's case, how about simple stuff like "color", "person", "place", "food", "cat", "dog", "stupid cousin"...
Or how about less simple stuff, like full geographical ontologies - city names, capture device ontologies - camera make and model.
The argument that is sure to erupt is "why? if everyone just tags everything, it'll all be easily findable anyways!" Wrong. Relationships between data - subject verb object - grammar - some structure is always needed, and here we have an opportunity to get in in the middle and do it right...
Otherwise, as Karl says, we will go from an ocean of files to an ocean of tags, and no closer to home.
(Google translation of Karl's entry. Beware. It's almost as good as if he'd written it in english himself... ;)
7:30am. Shall I sleep or just stay up now?








")




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}